ENTRADA - DNS big data analytics
ENTRADA (ENhanced Top-level domain Resilience through Advanced Data Analysis ) is a tool for analysing very large volumes of DNS data.
This is achieved by converting the DNS (which arrives in PCAP formatted files) to a more efficient columnar data format (Apache Parquet).
Analyzing the parquet data is done using a analytical query engine such Hadoop + Impala or Amazon Athena. ENTRADA has support for both SQL-engines.
All the workflow steps required to get from raw DNS data to Parquet data available for querying in a database are automated.
DNS data is converted, enriched and streamed into the database automatically, this means the data is ready to be analysed within minutes from being processed on the name server.
ENTRADA can be deployed on premise or in the cloud, the table below displays the possible options.
| Deployment | Storage | SQL-engine | on premise | Cloud |
|---|---|---|---|---|
| Hadoop | HDFS | Impala | yes | yes |
| AWS | S3 | Athena | no | yes |
| Local | local disk | - | yes | yes |
The DNS request and its corresponding response are combined into a single database row and enriched.
These step are performed during the data import process to help speedup later SQL-queries.
The required resources, such as the IP geolocation database, are downloaded automatically by ENTRADA.
The following details are added to each DNS query and response tuple.
- Geolocation (Country)
- Autonomous system (ASN) details
- Detection of public resolvers (Google, OpenDNS, Quad9 and Cloudflare)
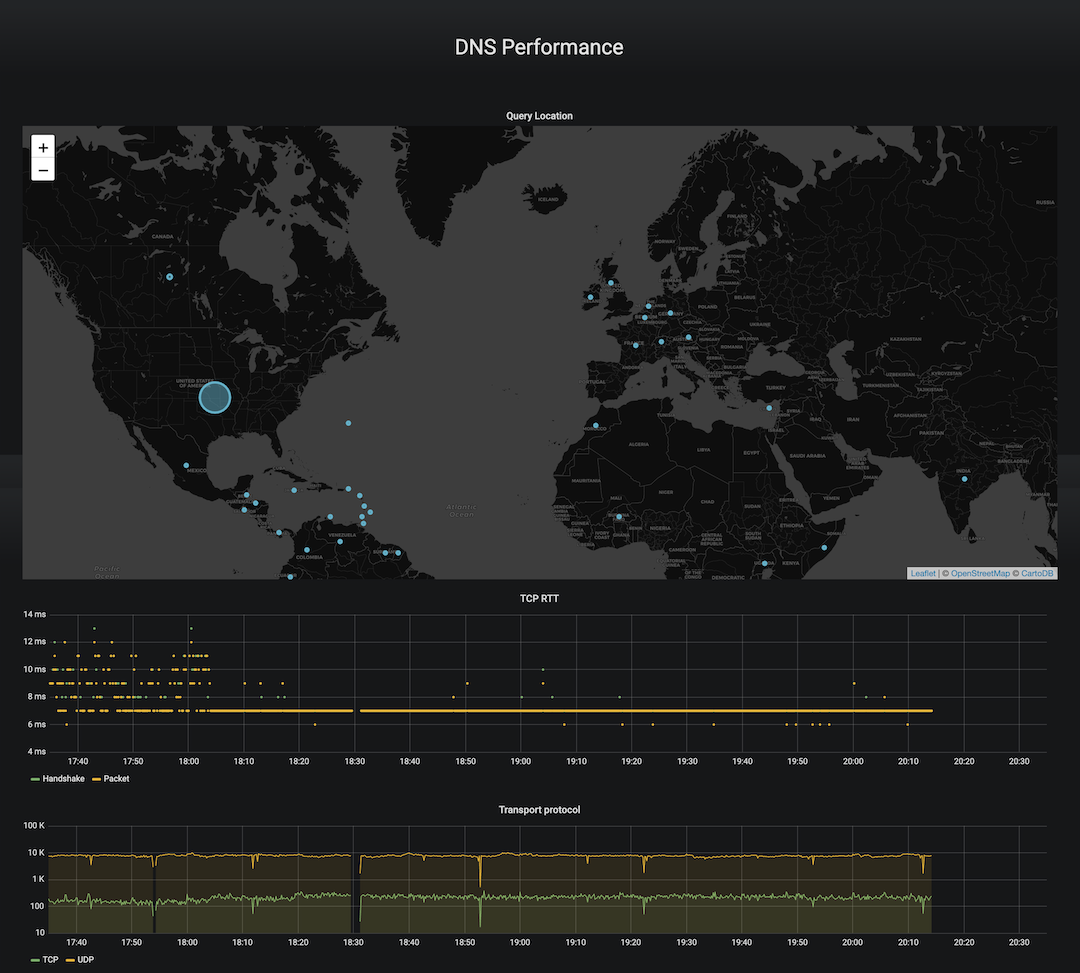
- TCP round-trip time (RTT)
Apache Impala, AWS Athena or Apache Spark can be used to analyse the generated Parquet data,
ENTRADA will handle all the required workflow actions such as:
- Load and archive PCAP files
- Convert and enrich data
- Create database schema and tables
- Create an S3 bucket
- Configure S3 security policy and encryption
- Create filesystem directories
- Move data files around
- Upload data to HDFS or S3
- Compact Parquet files on HDFS or S3
Making ENTRADA more efficient is supported by: JProfiler, the leading Java profiler